Published
- 9 min read
Part 2: How We Built Our Internal Developer Portal (Without Overengineering It)
Link Copied!
Share away.
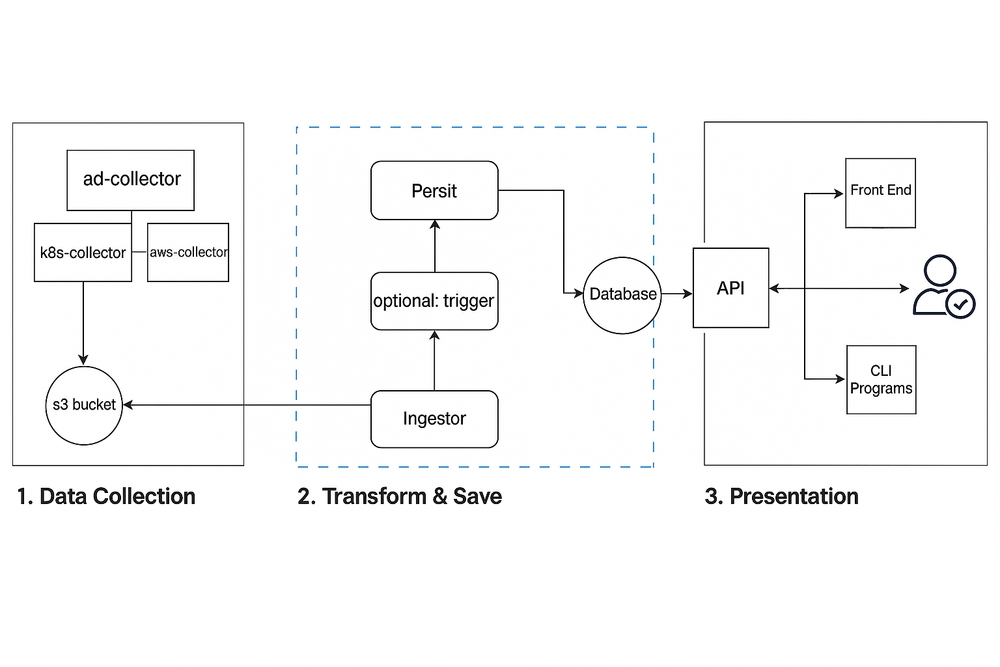
Recap
In Part 1, we talked about why we felt the need to build something ourselves — the pain points, the gaps in visibility, and the reality that off-the-shelf tools didn’t quite fit our size, shape, or workflows.
This post is about how we implemented the basic version of it.
Where to Start
Now that we had the freedom to build whatever the hell we needed, we could actually get creative.
Our first goal? Start mapping our estate. We needed to gather data that gave us a clear 1:1 relationship between services, the resources they ran on, and the teams or environments that owned them — spread across multiple AWS accounts, Kubernetes clusters, and namespaces. And yeah, we had a lot of them.
For us, each AWS account maps to an environment. We follow the usual AWS best practices with a well-structured org, so this part was at least consistent (ish). It’s worth noting that we’re primarily an AWS house — no GCP, aside from the odd backup store or experiment here and there.
But once you factor in:
- Multiple Kubernetes clusters
- Varying namespaces within each
- Serverless functions services sprinkled throughout
- And teams owning bits across accounts
…you get the idea. It was a spread across various places!.
So we started by getting a clear understanding of what data we needed, where it lived, and how to collect it in a way that made ownership and usage obvious.
No Tag, No Deploy
One of the biggest advantages we had going into this was that our organization had already standardized on internal deployment tooling — wrappers around IaC and CI pipelines that enforced certain conventions.
Most importantly: every deployable resource required a team tag to be set. No tag, no deploy. Simple as that!
This might sound small, but it was massive. It meant we could confidently map every single thing in our cloud estate — from Lambda functions to S3 buckets — back to a team.
Having that enforced at the pipeline level gave us a common thread across all environments, all resource types, and all teams. It turned a chaotic mix of cloud services into a pattern we could assert some standards onto, visualize, and reason about.
This gave us a huge head start when it came to designing our models — because we didn’t have to invent ownership logic from scratch. It was already there. We just had to expose it!
Early Domain Models
Once we had a rough idea of what data we needed, we had to figure out how to represent it in a way that actually made sense to engineers. This was one of the early benefits of building in house with complete freedom
We didn’t try to boil the ocean — we focused on the core things that mattered:
Team- The lowest unit of ownership. Everything had to roll up to a team.Service- These were things engineers actually deployed and maintained — likehttpservices orscheduled jobs.- Services had a type, which early on meant either 1 of
kubernetes(e.g.Deployments,CronJobs)serverless(mostly Lambda)
- Services had a type, which early on meant either 1 of
- Resource
- These were cloud-agnostic representations of the underlying infrastructure — the stuff that gets created under the hood:
- S3 buckets
- RDS instances
- DynamoDB tables
- Lambda functions
- …and anything else spun up via
Terraform,CloudFormationor otherautomation
- These were cloud-agnostic representations of the underlying infrastructure — the stuff that gets created under the hood:
- Product
- a parent relation which many Teams, Service and could pertain too
We intentionally kept the models broad, optional, and flexible. Not every service mapped neatly to a single resource or even a team. Some resources were orphaned and didn’t belong to any known service (yet). So we left room for that.
This early modelling helped us answer questions like:
- “Who owns this RDS instance?”
- “What services does this team actually run?”
- “Why does this S3 bucket even exist?”
Once we had these building blocks, we could start thinking about how to wire them together — and how to ingest and surface them!
Choosing Our Stack
With greenfield projects comes great responsibility…
In our case, most of the engineers on the project had solid experience across a bunch of programming languages — so we weren’t too fussed about which one to use. We put it to a democratic vote.
In the end, we went with Python, shocker, mostly for its simplicity.
We all valued being able to move fast without wrestling the language. It also helped that Python was already used in lots of parts of our existing infra, so it wasn’t a leap.
Plus, we knew that our 1:1 component-based approach meant we could always swap tech out later if we really needed to. Each part was its own thing — collectors, ingestors, API, frontend — so we weren’t locking ourselves into a monolith!
We didn’t do a giant matrix of tools or a six-month bake-off. We leaned on stuff we already knew, already used, or could learn quickly.
Here’s where we landed:
Backend- FastAPI - Lightweight, Python-based, and plays nicely with
OpenAPI.
- FastAPI - Lightweight, Python-based, and plays nicely with
Data models- SQLModel - A nice balance between Pydantic and SQLAlchemy. Type-safe enough, but not painful.
Storage- PostgreSQL - We started out reading straight from
S3, then moved toPostgresonce we wanted to process data and persist relations, see this post
- PostgreSQL - We started out reading straight from
Collectors- Generally python, running as
KubernetesCronJobsorAWS Lambdasscraping info from their deployed environment - Each one focused on pulling a specific type of data (e.g.
AWS resources,Kubernetes entities,AD groups).
- Generally python, running as
Ingestor- A Python app that consumed raw data from
S3done some relation lookups and then stored it into a database.
- A Python app that consumed raw data from
FrontendCI/CD- GitLab CI/CD - We reused our existing CI components. No need to reinvent that wheel.
We avoided complexity wherever possible. No fancy event buses, no plugin frameworks, no tech that didn’t earn its keep, at least yet!
It wasn’t about finding the perfect stack — just the one that let us ship and iterate without getting stuck.
Building the Collectors
Once we had a rough idea of the data we needed — and how we wanted to model it — the next step was actually collecting it.
We started simple: each collector was its own lightweight script, responsible for pulling data from a specific source and dumping it to S3 as JSON.
That’s it. No fanfare. No stream processing. Just: fetch, structure, store.
Each one ran independently — either as a Kubernetes CronJob or an AWS Lambda — depending on where it made the most sense to run. Some examples:
- A CronJob in our EKS cluster would list all Deployments and CronJobs across a set of namespaces.
- A Lambda in our AWS org would assume roles across accounts and pull lists of S3 buckets, RDS instances, etc.
- Another job would pull team and group data from Active Directory.
The idea was to break up the problem: instead of trying to collect everything in one giant job, we went with a bunch of small, focused components. Each collector knew how to talk to its system, format the output, and write to a shared bucket.
That way:
- We could schedule each one at its own cadence.
- Failures wouldn’t take the whole system down.
- We could iterate on them independently (or replace them entirely) without side effects.
s3://our-bucket-name/
└── aws-collector/
└── <aws-account-id>/
└── <region>/
├── s3.json
├── rds.json
└── k8s-collector/
└── <aws-account-id>/
└── <region>/
└── <cluster-name>/
└── <namespace>/
├── deployments/
│ └── <deployment_name>.json
└── cronjobs/
└── <cronjob_name>.json
This made it easy to debug, reason about, and test locally. It also gave us flexibility later when we started ingesting and enriching this data.
Ingesting the Data
Once the collectors were regularly dropping data into S3, we needed a way to stitch that data together, enrich it, and load it into something we could query.
That’s where the ingestor came in.
It was a lightweight Python app that ran on a schedule — it would:
- Scan S3 for the latest files across each source.
- Parse them and do some light transformation.
- Match resources to services, services to teams, and so on.
- Upsert the result into our PostgreSQL database.
The goal wasn’t to build a full-blown ETL pipeline — just something fast, simple, and good enough to populate the core models we needed to power the API.
Exposing the Data
Once the ingested data was sitting in Postgres, the next question was “How do people/systems actually consume it?”
We didn’t want people writing SQL or digging through S3. The goal was always to make this stuff easily accessible — so we built a thin API layer on top of the core models.
We used FastAPI, which made it easy to expose endpoints with decent OpenAPI docs out of the box. Each route mapped pretty closely to the domain models we’d defined earlier:
/api/v1alpha/teams – list all teams (and the services/resources they own)
/api/v1alpha/services – list service metadata by type, team, or environment
/api/v1alpha/resources – list cloud resources (e.g. S3, RDS, etc.)We added some lightweight filters and relationships (like joining services to teams), but kept the logic minimal — this wasn’t meant to be a GraphQL-style deep querying engine.
The idea was simple: Make it easy to answer questions without needing to know how the data got there.
And once the API existed, we could plug it into anything:
- Our internal frontend
- Scripts
- Slack bots
- CLI tools
We treated it like a utility — boring, stable, and always on.
A Frontend we were proud of
With the API in place, we built a proper frontend to sit on top of it — not just a scrappy dashboard, but a modern, responsive internal portal.
Thanks to @Reikon95, who joined us mid-project, we were able to turn our prototype into something genuinely polished. The portal had proper navigation, responsive layout, and real UX care — not just raw data dumped into a table.
We used:
- Vite for fast builds and dev experience
- React for structure and familiarity
- Shadcn-ui to deliver clean, modern components without having to build a design system from scratch
- Tailwind to keep styling fast and flexible
The frontend surfaced our domain models in a way that was actually useful:
- A Service Catalog, filterable by team, type, and environment
- A Team View, showing what a squad owns and runs across environments
- A Resource Browser, letting you slice by tag, type, region, or ownership
It made all the backend work feel real by presenting it in a very lovely way!
It wasn’t overengineered. It didn’t try to be Backstage. But it worked — and people liked it!