Published
- 5 min read
Part 2: Benchmarking UUID Formats, Data Types and Engines
Link Copied!
Share away.
Recap
In Part 1, I explained why picking the right UUID format upfront matters more than it might seem. It affects your choice of SQL engine, the shape of your schema, and how well your system scales.
Now it’s time to break down the options, test them out, and land on a decision that fits.
Relevant Data
Before looking at specific formats, it’s worth reviewing the data types that impact how these IDs behave in relational databases.
Storage Data Types
| Type | Pros | Cons |
|---|---|---|
CHAR(36) | Human-readable, works out of the box | Large (36 bytes), inefficient indexing, hyphens add extra weight |
BINARY(16) | Compact (16 bytes), fast indexing | Not human-readable, encoding/decoding overhead |
BIGINT | Super compact (8 bytes), fast ops, great for Snowflake or increment | Not globally unique, limited range (2⁶⁴), can’t store text-based IDs |
UUID | Native in Postgres, compact (16 bytes), optimized ops | Postgres-only, not portable |
TEXT/VARCHAR | Flexible, supports alphanumeric formats like NanoID | Slower queries, inefficient indexes |
INTEGER | Smallest size (4 bytes), fastest indexing and sorting | Not globally unique, predictable/guessable, capped at 2³² |
Formats Considered
Time-Based ID Formats
These are naturally sortable and often better suited for distributed systems:
- UUIDv7 — Time-based UUIDs designed for better indexing and ordering
- Snowflake ID — Widely adopted format offering high throughput and ordering
Non-Time-Based ID Formats
These focus on uniqueness, simplicity, or flexibility:
- UUIDv4 — Classic random UUIDs. Simple, but fragmentation-prone
- NanoID — Short, URL-safe string format with good entropy
- Auto-increment Integer — Fast and easy, but doesn’t scale across distributed systems
Benchmarks
This section covers results from two dimensions of testing:
- Client-side ID generation performance (no database interaction)
- Database-integrated performance across real operations like inserts, reads, updates, deletes, pagination, and concurrency
All benchmarks were recorded and visualized using matplotlib.
ID Format Generation Times
To start, I wanted to measure how long it takes to generate a single IDs for each format. Since ID generation happens client-side (with zero database interaction), this gives us a raw view of how efficient each format is — independent of the SQL engine we choose.
It’s worth noting that Auto-increment IDs are typically generated by the database itself, so they don’t appear in this benchmark. More importantly, auto-increment isn’t really suitable for distributed systems — which makes it a poor fit for our use case anyway.
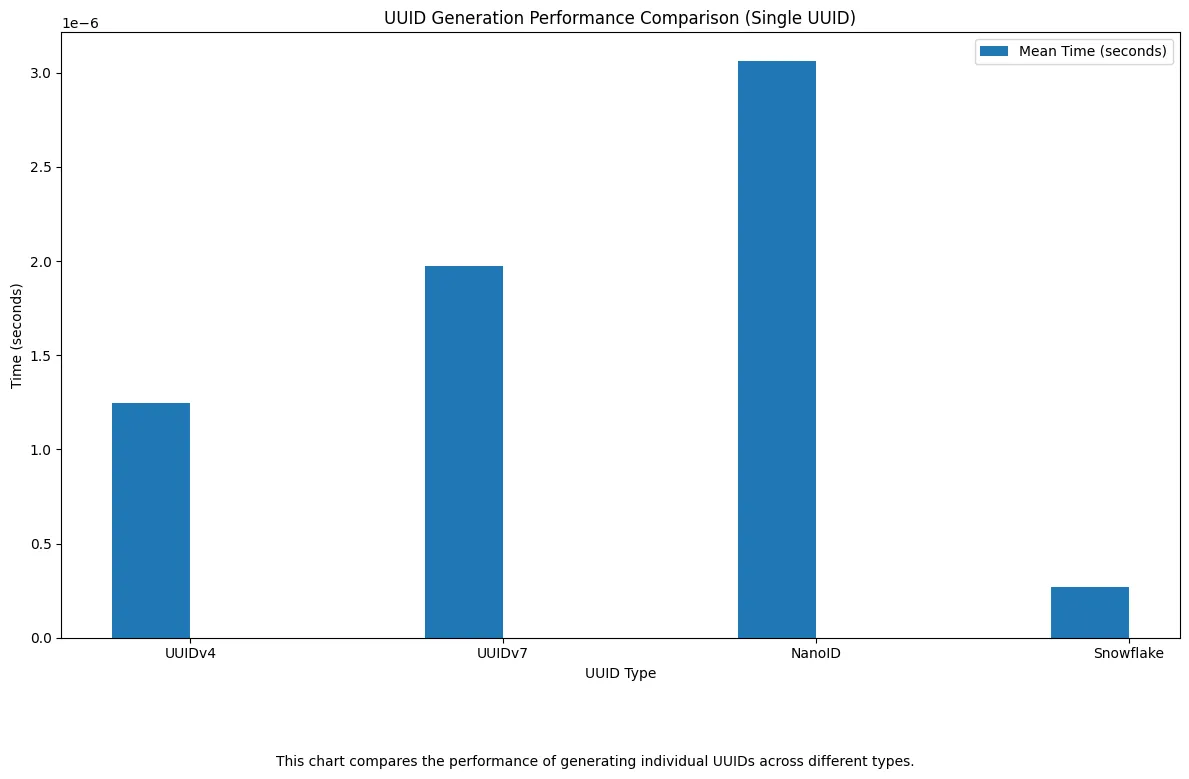
As we can see,
Snowflake IDswere the fastest to generate by a wide margin.UUIDv4andUUIDv7were both reasonably fast, withUUIDv7offering the added benefit of sortability.NanoID, while secure and compact, had noticeably slower generation times.
Functional Performance Testing
So next up, we’re adding database interactions into the mix.
After benchmarking raw ID generation, I wanted to see how things hold up when you start doing “real application” work — insertions, reads, updates, deletes, and concurrent operations.
To test this, I built a small Python harness that defined table schemas for each format and ran the same set of operations across two local SQL engines — Postgres and MySQL — each spun up in its own container. The goal was to keep things consistent, repeatable, and as close to real-world conditions as possible.
👉 TODO: [Link to the test repo or notebook when ready]
Storage Notes:
UUIDv4&UUIDv7are stored usingPostgresnativeUUIDtype- In
MySQL, both UUID versions are stored asCHAR(36) SnowflakeID is stored in both engines as aBIGINTNanoIDis stored in both engines as aVARCHAR(21)Auto-incrementis stored in both engines as anINTEGER
CRUD Times (per engine)
Read
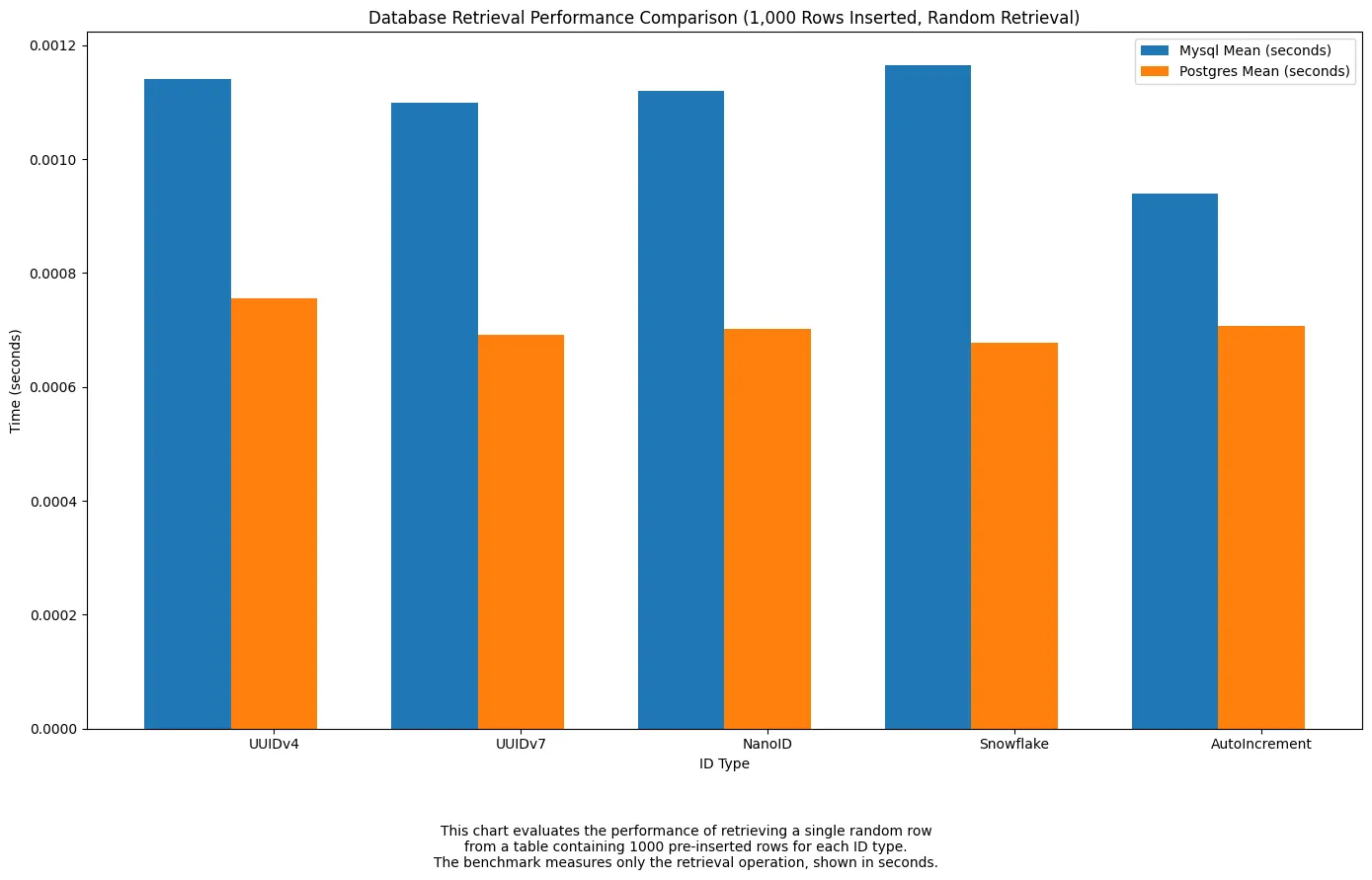
Overall reads are overall the same with some faster results on postgres!
Insertion
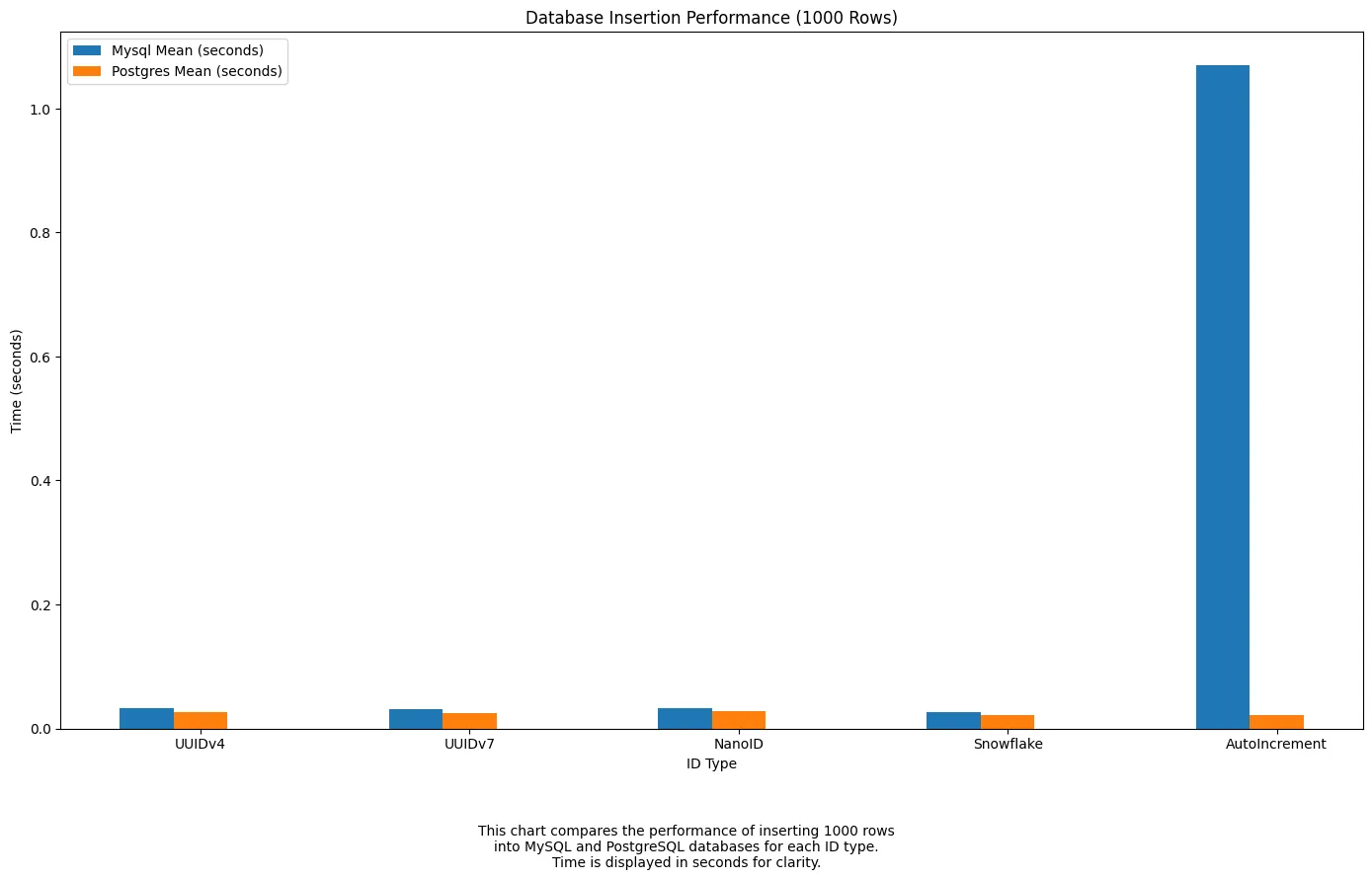
As we can see, all formats performed similarly for insertions in both
PostgresandMySQL— with one exception: Auto-increment was significantly slower inMySQL. This is likely because the database itself is responsible for generating the ID, introducing additional overhead compared to formats likeUUIDv7orSnowflake, which are generated client-side before insert. It’s a good reminder that engine-managed IDs don’t always guarantee faster writes.
Update
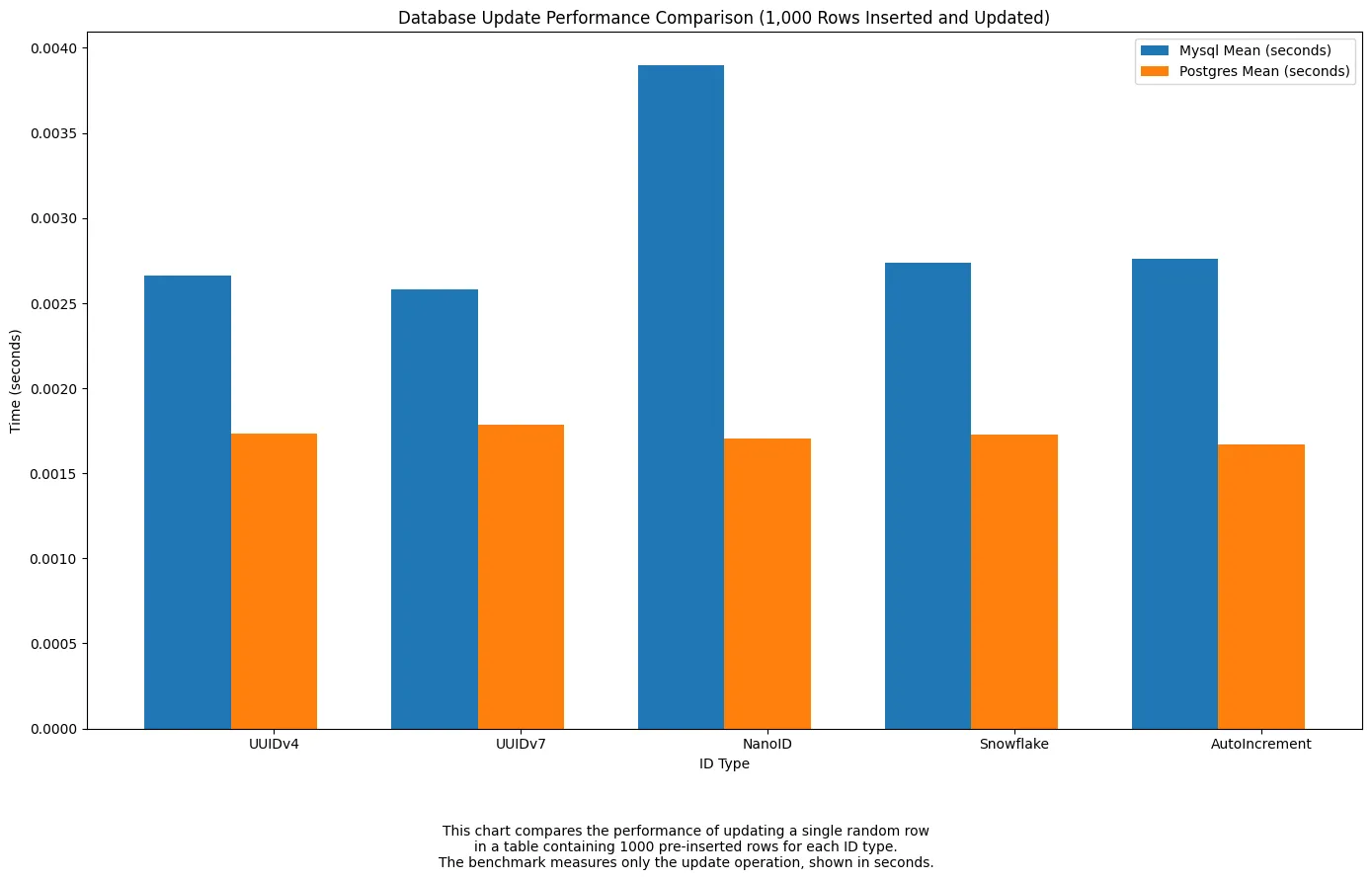
Update performance was fairly consistent across all formats in
Postgres, with only slight variation. InMySQL,NanoIDwas notably slower to update — likely due to its longer string format and variable indexing cost.UUIDv7,UUIDv4, andSnowflakeall performed similarly and reliably across both engines.
Delete
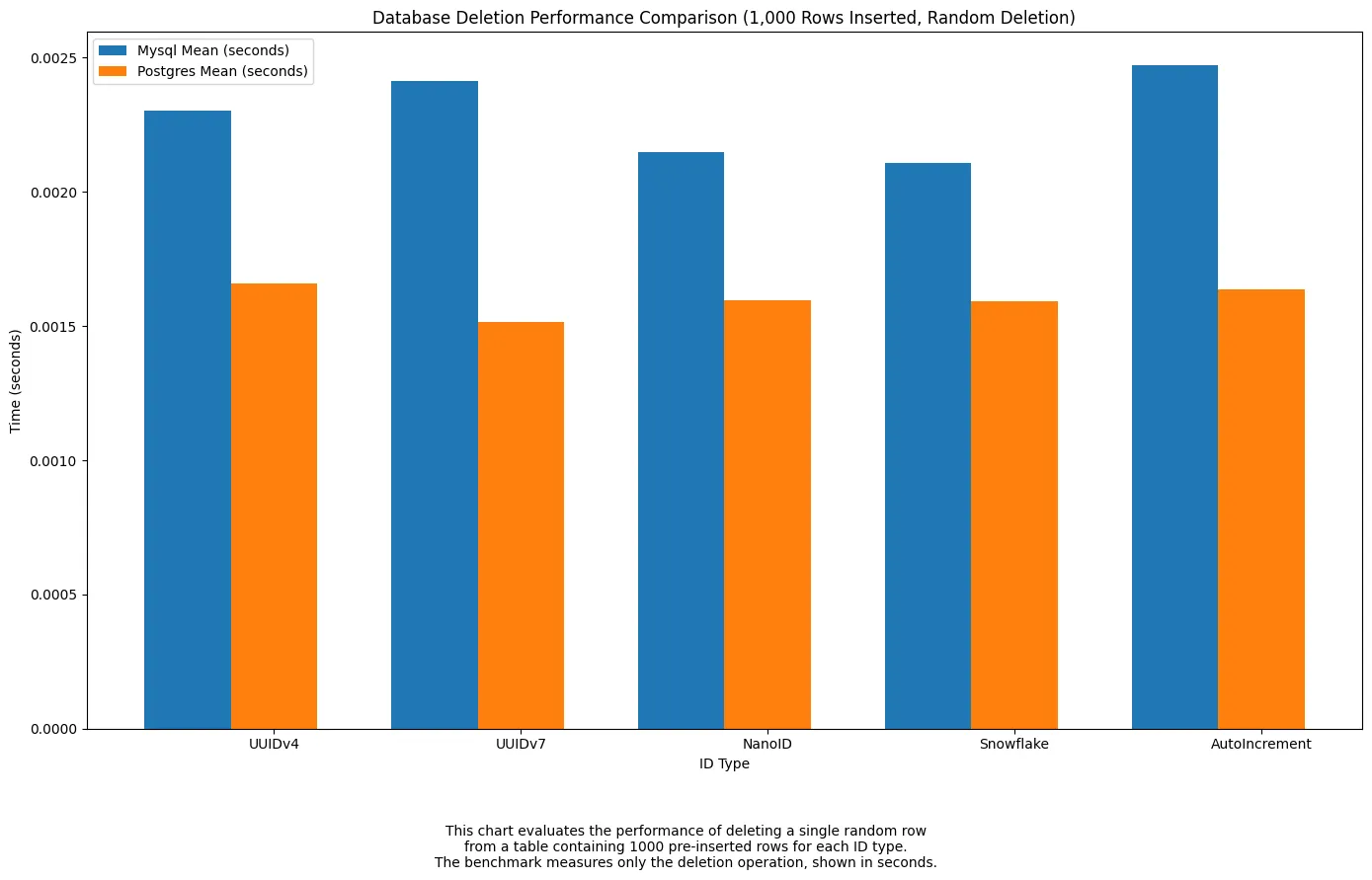
For deletes, we can see all formats showed similar deletion performance in
Postgres, with only minor variation. InMySQL,UUIDv7andUUIDv4performed slightly better than the others, whileAuto-incrementwas consistently the slowest. Overall, Postgres offered faster and more stable deletion times across all ID types.
Pagination Times
Pagination evaluates the performance of retrieving smaller subsets of data across multiple queries using LIMIT and OFFSET.
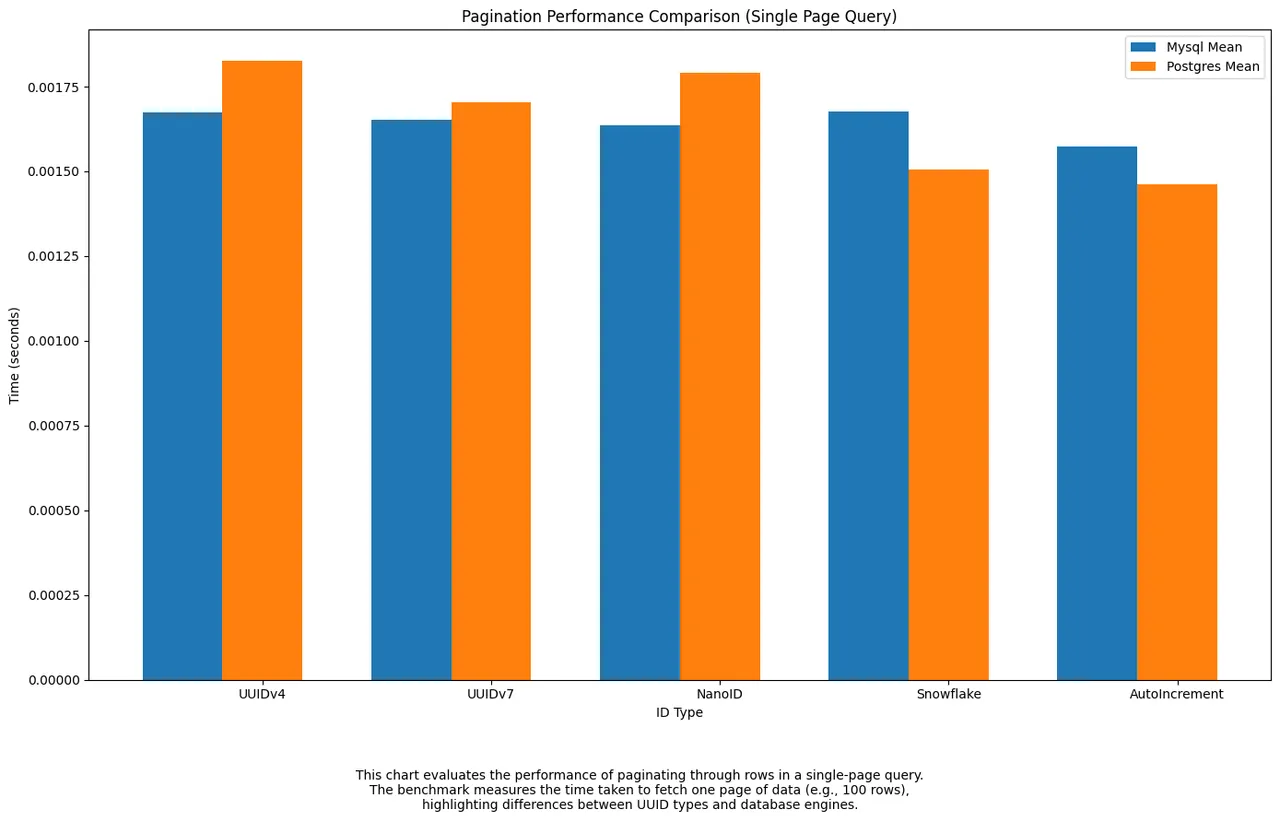
SnowflakeandAuto-incrementdelivered the fastest pagination times overall, especially inPostgres.UUIDv7performed solidly but slightly slower than expected, whileNanoIDandUUIDv4lagged behind in both engines. Time-ordered formats like Snowflake likely benefit from more cache-friendly and index-aligned data access during pagination.
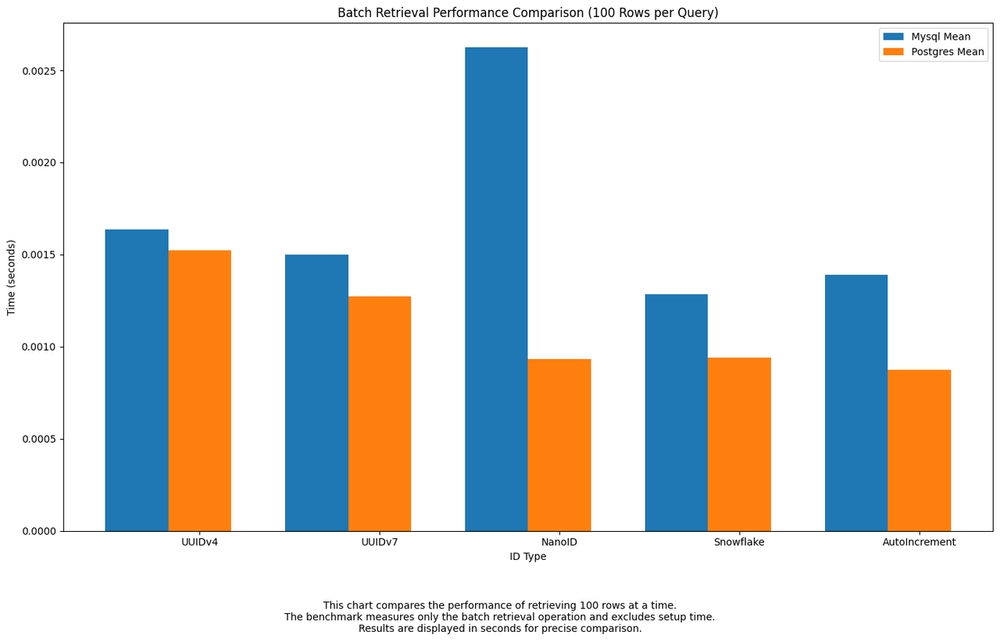
Batch Retrieval
Batch retrieval measures the speed of fetching a large, fixed number of rows in a single query.
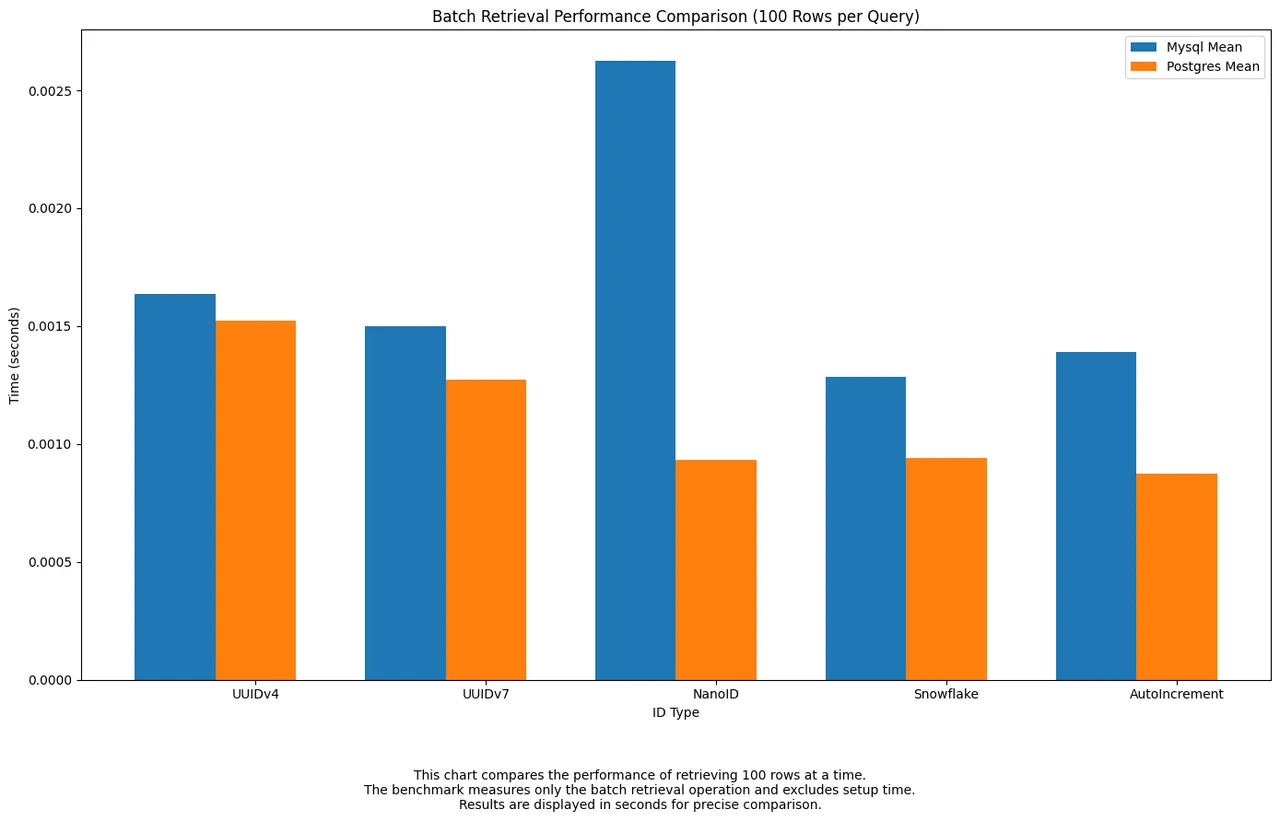
UUIDv7,Snowflake, andAuto-incrementall delivered fast batch read times, particularly inPostgres.NanoIDshowed a sharp slowdown inMySQL, likely due to its string-based indexing overhead. Overall,UUIDv7offered strong, balanced performance across both engines.
Concurrent Updates
Postgres is a clear winner here due to MVCC
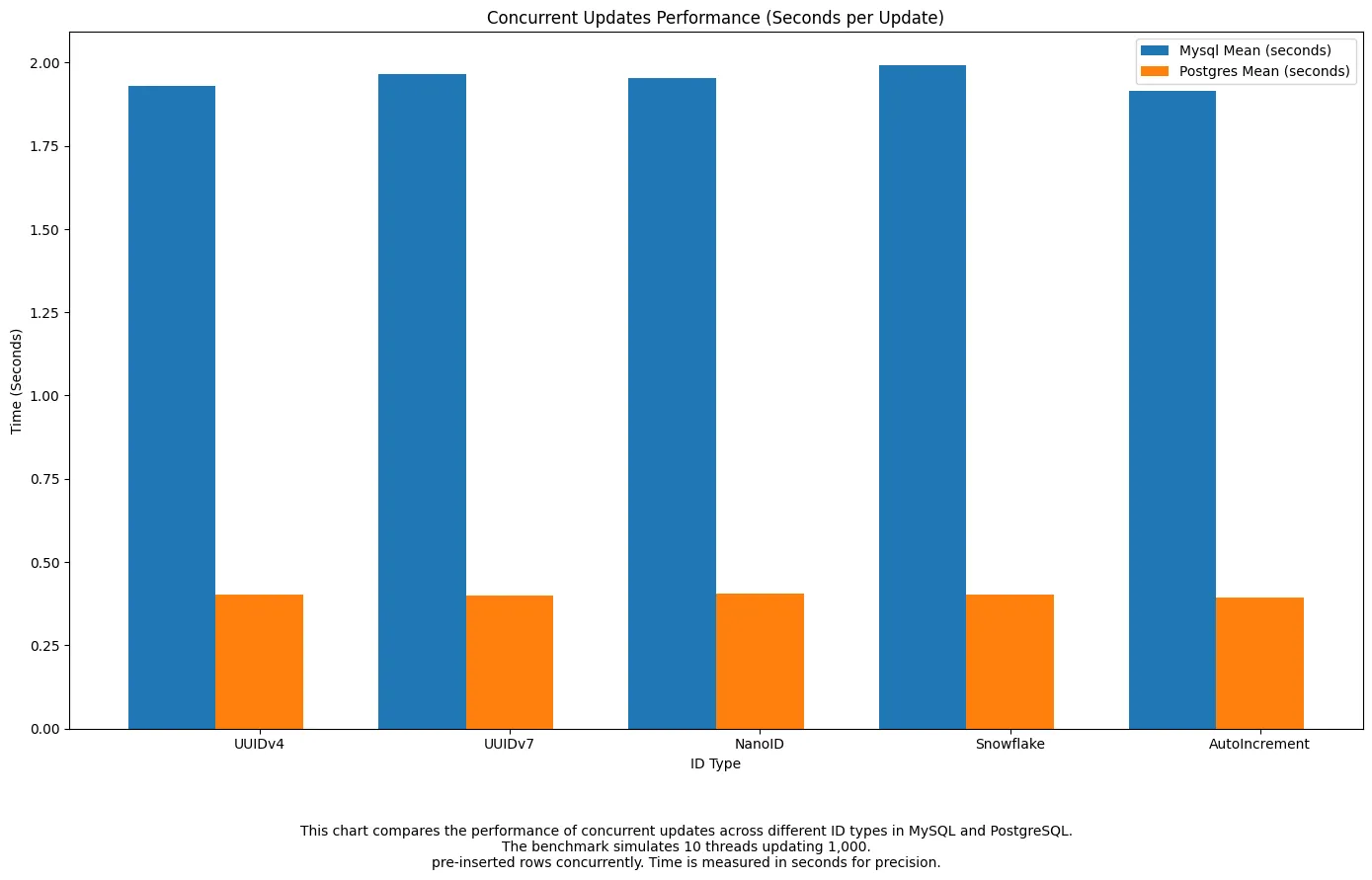
Here,
UUIDv7andSnowflakeperformed the best under concurrent write pressure in bothMySQLandPostgres. Thanks to MVCC, Postgres handled concurrency consistently well.UUIDv7maintained both index health and write speed — making it ideal for high-concurrency systems.
Potential Options
Based on this testing, the shortlist came down to:
Postgreswith nativeUUIDtype +UUIDv7PostgreswithBIGINT+Snowflake IDsMySQLwithBIGSERIAL+UUIDv7orUUIDv4
End Decision
In the end we chose Postgres + UUIDv7, because it gave us:
- Time-ordered UUIDs with great performance
- Native storage support (
UUID) and compact indexing - No coordination overhead
- Better query consistency under load
- zero cost differnce compairing it to MySQL hosted instances on ASW
Closing Thoughts
This research helped us make a small but foundational decision early, and avoid expensive rewrites later. UUIDv7 might not be for everyone, but if you care about pagination, performance, and clean indexing in Postgres, it’s a strong default.