Published
- 3 min read
Part 1: Why UUID Format Even Matters
Link Copied!
Share away.
Introduction
So, I recently dug into UUID formats — how riveting… — for a new internal product I’m leading. After sketching out our early data models, the next step was figuring out what our SQL schema should look like.
One thing that sounds minor but turns out to be pretty influential? The ID format. Yep — the choice of UUID format can affect:
- Which SQL engine makes the most sense
- What data types you store IDs as
- How your database handles reads, writes, and growth over time
This wasn’t just about theoretical optimization. I’m all for avoiding early abstractions when it makes sense, but let’s be real — migrating from one UUID format to another after going to production is no small lift. The effort required to rewrite IDs, update foreign keys, reindex tables, and ensure referential integrity could be massive. I didn’t want us to sleepwalk into that kind of tech debt just because we didn’t pause to choose the right format early on.
Before going deeper, I’ve got to shout out a few great articles that gave me a solid idea of where to start my research and testing:
- The Problem with Using a UUID Primary Key in MySQL
- Features of ID Formats for Web Applications
- Benchmarking ID Generation Libraries in Python
Why This Matters
This wasn’t my first rodeo with backend systems, but I wanted to get this one right from day one. Here’s what made the decision important:
- ID Format Affects SQL Engine
Some formats — like Postgres-native UUIDs or BIGINT with Snowflake IDs — are optimized for specific engines. If you care about performance, that optimization matters. - Storage Types Vary a Lot
CHAR(36)IDs eat up space and slow things down. UUIDs stored natively are better.BIGINTs are super efficient — but not always flexible enough. - Throughput Isn’t an Afterthought
Sure, we’re not running a firehose of writes — but we care about fast reads, stable indexes, and efficient pagination. The ID format influences all of that. - Internal Lessons Helped
Other teams in our org had hit pain points with UUIDv4 (especially around index fragmentation and query latency). Many had started switching to UUIDv7 for better ordering and retrieval.
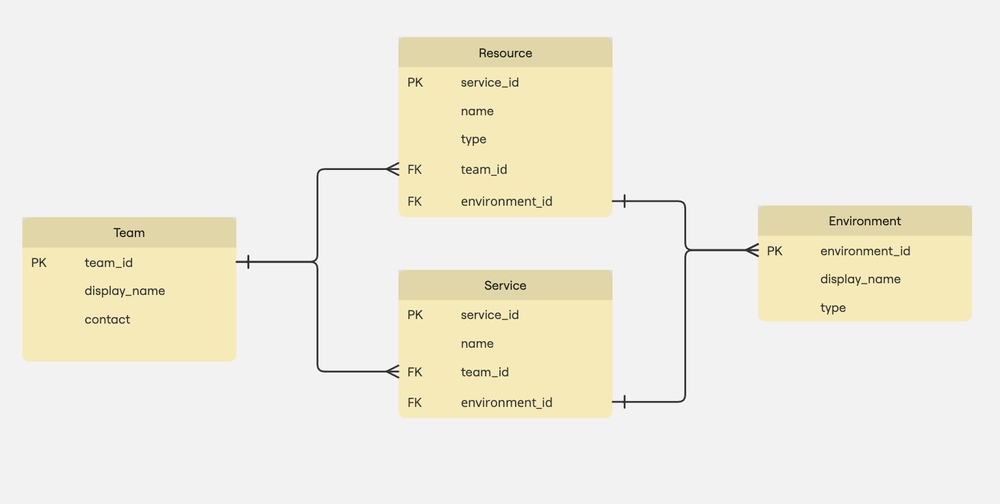
Separation of Concerns: Format vs Storage
When working with relational databases, it’s important to separate how an ID is generated from how it’s stored.
- ID format refers to the logic used to create the ID — like
UUIDv4,UUIDv7,NanoID, orSnowflake. - Storage type is the database column type that physically holds that ID — like
CHAR(36),UUID,BINARY(16), orBIGINT.
Why this matters:
- Two teams might both use UUIDv4, but if one stores it as
CHAR(36)and the other usesBINARY(16), their performance characteristics will be very different. - Some engines (like Postgres) have native support for UUIDs, while others (like MySQL) treat them as plain text or binary blobs.
This distinction is specific to relational databases, where schema definitions and index structures are tightly coupled with performance. In a schemaless NoSQL setup, the trade-offs might look different — but for SQL, this separation of concerns is critical.
Our Requirements
Here’s what mattered for our project:
- Insertion/Deletion: We expect fewer than 5,000 ops a day. Speed isn’t life-or-death, but no one wants drag.
- Retrieval: Fetching records — especially paginated or batched ones — needs to be quick.
- Scalability: We want to choose something that’ll still hold up when the dataset grows 10×.
In the next part, I’ll walk through the different formats we considered, how we stored them, and what our benchmark testing told us.