Published
- 10 min read
Goodbye Docker+Machine: Running High-Scale GitLab Runners on EKS with Karpenter
Link Copied!
Share away.
Overview
One of the more interesting challenges we faced during our migration to a dedicated Kubernetes cluster for GitLab CI runners was a subtle timing mismatch between node readiness and TLS bootstrapping.
This cluster was designed specifically to handle GitLab CI workloads, which meant dealing with intense, unpredictable bursts—thousands of short-lived pods spinning up and shutting down across the day.
To scale efficiently, we turned to Karpenter, AWS’s node lifecycle controller for Kubernetes. Though still in alpha at the time, it offered the most promising path to fast, cost-effective, and responsive autoscaling for our compute-heavy workloads.
But in practice, we hit a hidden race condition: one that quietly disrupted TLS connections and led to unpredictable node scheduling behavior.
The Problem
Analogy
Imagine you’re at a traffic light. It turns green, so you go. But right as you drive through, another car slams into you from the side—because although your light said it was safe, the intersection wasn’t actually clear yet.
That’s exactly what was happening here: the node’s “green light” (the Ready state) was being trusted by the runner, but in reality, the node wasn’t ready to safely receive workloads. The crash was inevitable.

Our Case
When there was a sudden influx of CI jobs, Karpenter reacted by scaling up new compute nodes. This is expected. But some jobs immediately fail with a cryptic TLS error, such as:
Job failed(system failure): prepare environment: setting up trapping scripts on emptyDir: error dialing backend: remote error: tls: internal error.Check https://docs.gitlab.com/runner/shells/index.html#shell-profile-loading for more informationWe saw this repeatedly during early morning pipeline spikes, with the pattern triggering a Datadog alert almost daily around 6am—right as our infra repo’s scheduled jobs kicked in.
At a glance, the cluster appeared healthy. Nodes reported as Ready. But when we dug deeper, we saw a race: the kubelet’s Certificate Signing Request (CSR) was still pending or just recently approved—even though Kubernetes had marked the node as schedulable.
That timing mismatch caused pods to be scheduled before the kubelet was truly ready. The GitLab Runner would then fail to establish a secure TLS connection, crashing the job instantly.
Here’s a real-world view of the issue:
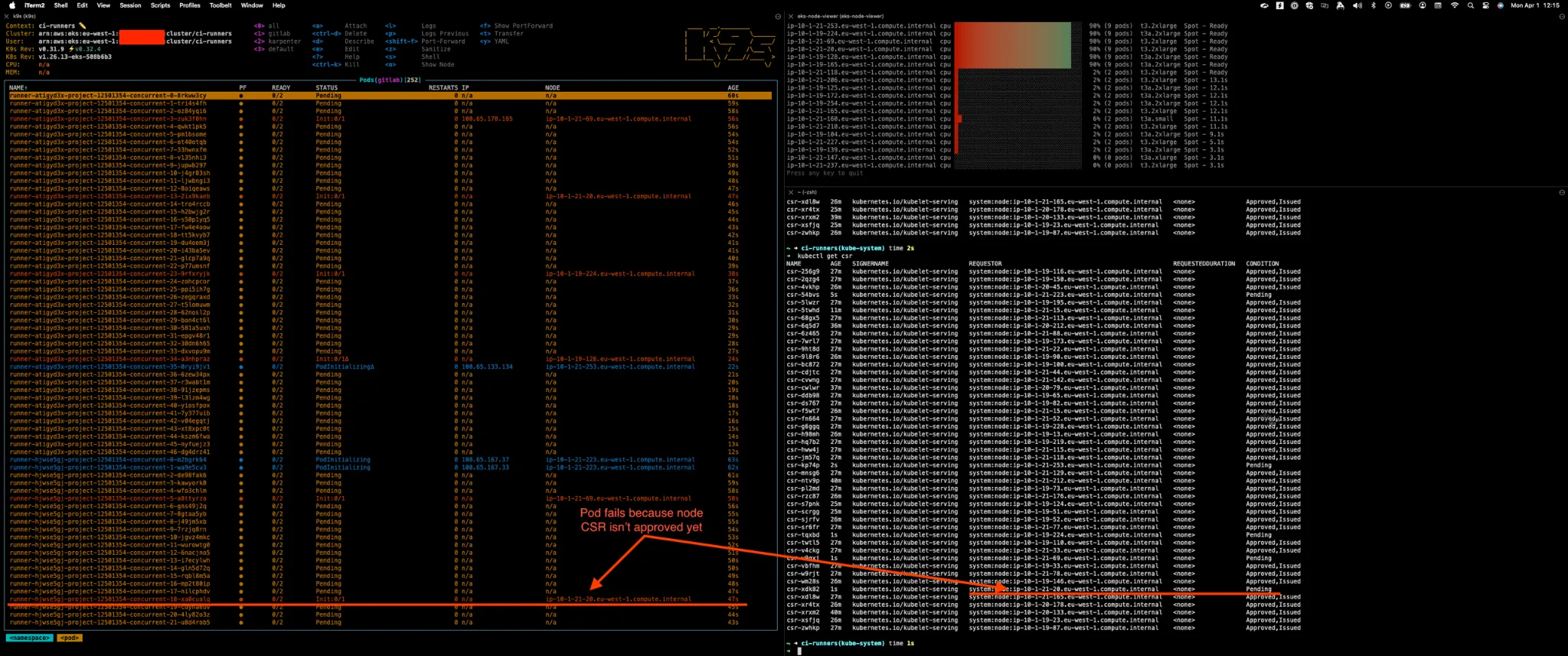
You can see that jobs were scheduled on nodes like ip-10-1-21-208.eu-west-1.compute.internal, whose CSRs hadn’t been approved yet—resulting in TLS handshake errors and pod failures.
Patch and Pray
Once we understood the core problem, we considered whether any application-level settings could help mitigate the issue. After all, this was affecting production services and reliability—so we were eager to find a solution as quickly as possible.
We tested several runner-level options:
poll_timeout— This setting defines the amount of time, in seconds, that needs to pass before the runner times out attempting to connect to the container it has just created. It’s useful when queuing more builds than the cluster can handle at once. The default is180seconds. We increased this to720seconds, hoping it would give nodes more time to become fully ready before the runner gave up.retry_limits— This controls the maximum number of attempts to communicate with the Kubernetes API. The retry interval between each attempt follows a backoff algorithm starting at 500 milliseconds. We bumped this up to35retries, aiming to give the runner additional time to recover from transient API failures during node spin-up.
None of these had a meaningful impact. Jobs still failed if they landed on nodes whose kubelet CSRs hadn’t yet been approved.
It became clear the problem wasn’t that GitLab Runner was failing to wait—it was that Kubernetes itself had prematurely declared the node Ready even though the TLS trust (via CSR approval) wasn’t complete.
Native Node Readiness Isn’t Enough
When a new node joins a Kubernetes cluster, it undergoes a series of steps to become schedulable:
- The kubelet starts on the node and initiates a Certificate Signing Request (CSR) to the Kubernetes control plane.
- The control plane processes this request. Depending on the cluster configuration, the CSR may be auto-approved or require manual approval.
- Once approved, the kubelet receives a signed client certificate, allowing secure communication with the API server.
- The node begins reporting its status, and the control plane updates its condition to Ready.
The problem? Kubernetes often marks the node as Ready before step 3 fully completes — that is, before the kubelet receives its signed certificate. From the control plane’s perspective, the node is up and healthy. But the kubelet is not yet fully trusted, and any attempts by the scheduler to place workloads on it may fail if those workloads depend on a secure TLS connection.
This creates a subtle race condition between perceived readiness and actual readiness.
As per the Kubernetes documentation on node lifecycle, node readiness is determined by the kubelet posting a Ready status in its heartbeat. However, that signal can precede the completion of TLS bootstrapping — especially in fast-scaling environments where provisioning and node registration happen in rapid succession.
This behavior is entirely native to Kubernetes. Tools like Karpenter and even the Kubernetes scheduler itself trust the Ready signal as sufficient to schedule pods. But in reality, the kubelet may still be finalizing its secure identity.
Why Native Readiness Checks Didn’t Help
Before building our own solution, we evaluated whether Kubernetes offered any native mechanisms to delay pod scheduling until a node was truly ready. If possible, this could have avoided the need for a self-implemented workaround.
We found two candidates:
- Node Readiness Gates (deprecated): This concept allowed custom controllers to delay marking a node as
Readyuntil certain conditions were met. However, it was only ever supported on Google Kubernetes Engine (GKE) and never became part of upstream Kubernetes. It is now deprecated and not available in AWS EKS, making it a dead end for our use case. - Pod Readiness Gates: These allow pods to declare readiness conditions backed by custom controllers. Unfortunately, they only apply after the pod has been scheduled. Our issue occurs before that point—when the scheduler assigns a pod to a node whose kubelet hasn’t fully completed its startup and CSR approval.
This confirmed we needed to handle the node readiness race condition ourselves.
Our Solution
To solve this problem, we created a small Python service and named it appropriately: kube-taint-manager. Its sole job is to monitor Certificate Signing Request (CSR) events in the cluster and remove a taint from nodes once their kubelet has been issued a certificate.
This allows us to delay scheduling workloads on nodes until they’re actually ready — avoiding the race where a pod is assigned to a node that isn’t functional yet.
How it works
We use the Karpenter startupTaints feature to apply the following taint to new nodes in our CI node pool:
node.kubernetes.io/csr-pending=true:NoScheduleHere’s the flow:
- A new node is created with the startup taint applied.
- kube-taint-manager runs in the cluster and watches CSR events.
- When it detects that a node’s CSR is approved and the certificate is issued, it removes the startup taint from that node.
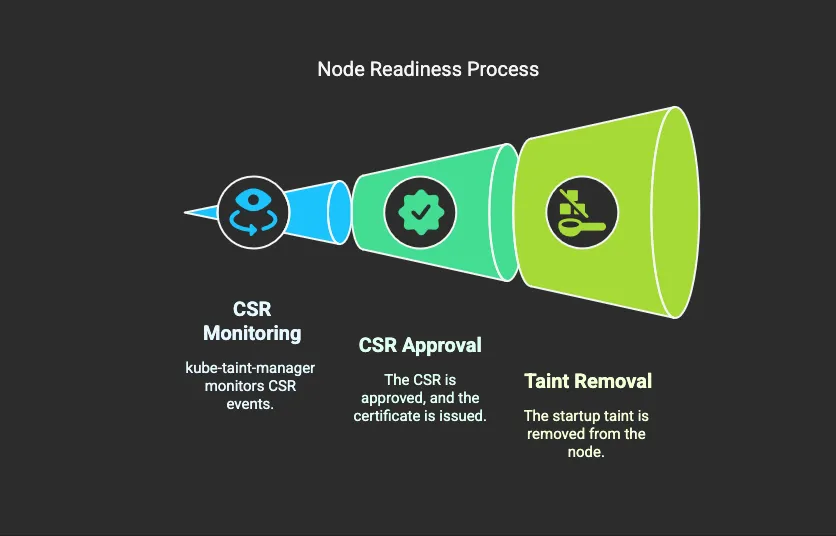
This ensures the node is not considered for scheduling until its kubelet is authenticated and fully registered with the cluster — effectively eliminating the TLS race condition.
Deployment Details
We containerized the Python logic and wrapped it in a minimal Helm chart for simple deployment. It runs as a lightweight Deployment with 1–2 replicas and uses a service account with scoped RBAC permissions:
# https://kubernetes.io/docs/reference/access-authn-authz/certificate-signing-requests/#authorization
rules:
# Required to read CertificateSigningRequests
- apiGroups: ["certificates.k8s.io"]
resources: ["certificatesigningrequests"]
verbs: ["get", "list", "watch"]
# Required to patch node taints
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "patch"]Source Code
- main.py
"""
Module to monitor Node Certificate Signing Requests and remove startup taints when issued.
"""
import argparse
from kube_taint_manager.lib.k8s_client import KubeClient
def main():
"""
Main function to parse arguments and initialize KubeClient.
"""
parser = argparse.ArgumentParser(
description="Monitors Node Certificate Signing Requests and removes startup taints when issued"
)
parser.add_argument(
"--no-dry-run",
action="store_true",
help="Disable dry run and perform actions"
)
args = parser.parse_args()
k8s_client = KubeClient(dry_run=not args.no_dry_run)
# Monitor & Respond to CSR events
k8s_client.watch_csrs()
if __name__ == "__main__":
main()
- lib/k8s_client.py
"""
Client module for interacting with Kubernetes.
"""
import os
from pathlib import Path
from kubernetes import client, config, watch
from kube_taint_manager.lib.logger import logger
class KubeClient():
""" Common functions for interacting with Kubernetes. Docs at https://raw.githubusercontent.com/kubernetes-client/python/master/kubernetes/docs/CoreV1Api.md """
def __init__(self, dry_run: bool = True):
"""
Initializes the KubeClient instance.
Parameters:
dry_run (bool): Whether to run in dry-run mode (no changes will be made).
"""
# Load kube config from either the cluster or .kube file (local)
if os.path.isdir(f"{Path.home()}/.kube"):
config.load_kube_config()
else:
config.load_incluster_config()
# Create authenticated client
self.core_v1_client = client.CoreV1Api()
self.cert_api = client.CertificatesV1Api()
if dry_run:
logger.info("KubeClient initialized with dry-run")
self.dry_run = "All"
else:
logger.info("KubeClient initialized")
self.dry_run = None
def watch_csrs(self):
"""
Watches for certificate signing request (CSR) events and processes them.
For each CSR event:
- If the CSR is approved and associated with a node, removes a specific taint from the node.
"""
w = watch.Watch()
for event in w.stream(self.cert_api.list_certificate_signing_request):
csr = event["object"]
logger.debug(f"Got CSR event for username: {csr.spec.username}")
# Skip pending CSRs
if not csr.status.conditions:
logger.debug("CSR is still pending, skipping")
continue
# Skip CSRs without an associated certificate
if not csr.status.certificate:
logger.debug("CSR has no associated certificate yet, skipping")
continue
# Process CSRs associated with nodes
if csr.spec.username.startswith("system:node:"):
node_name = csr.spec.username.replace("system:node:", "")
creation_time = csr.metadata.creation_timestamp
for condition in csr.status.conditions:
if condition.type == "Approved":
completion_time = condition.last_update_time
completion_duration = completion_time - creation_time
logger.debug(f"{node_name}: {completion_duration.total_seconds()} seconds")
self.remove_node_taint(node_name, "node.kubernetes.io/csr-pending=true:NoSchedule")
def remove_node_taint(self, node_name: str, taint_name: str):
"""
Removes a specified taint from a given node.
Parameters:
node_name (str): The name of the node.
taint_name (str): The key of the taint to be removed.
"""
try:
node = self.core_v1_client.read_node(name=node_name)
except client.rest.ApiException:
logger.debug(f"Node {node_name} does not exist, skipping.")
return
taints = node.spec.taints or []
for taint in taints:
if taint.key == taint_name:
if self.dry_run:
logger.info(f"Dry run enabled: Node {node_name} taint {taint_name} would have been removed")
else:
taints.remove(taint)
logger.info(f"Removing taint {taint_name} from node {node_name}")
self.core_v1_client.patch_node(name=node_name, body=node)
break
From Sandbox to Stability
Before rolling out to production, we tested this approach in our sandbox environment to validate the effect of our startup taints and kube-taint-manager.
The results were immediate:
“Ran about 600 jobs with zero errors. Goodbye TLS errors.”
Once verified, startup taints were enabled for Karpenter nodes in our GitLab CI-dedicated cluster.
At the same time, we made a key change to Karpenter’s configuration: the range of EC2 instance types it could launch was tightened to favor larger, more capable nodes. Previously, Karpenter had access to a wide array of smaller instances—flexible in theory, but in practice, this caused excessive node churn during CI spikes, as many small nodes were rapidly provisioned and terminated.
By shifting toward larger instance types, Karpenter could make smarter provisioning decisions. This reduced the total number of autoscaling events during high-demand periods, leading to a more stable and predictable cluster.
Results
- TLS handshake failures were completely eliminated
- Karpenter began provisioning fewer, beefier EC2 instances
- Node churn decreased significantly
- CSR traffic dropped, reducing load on the control plane
- Pod scheduling became more stable and predictable
This marked the resolution of a long-standing and painful reliability issue in our CI infrastructure.
From TLS Wins to Image Pull Failures
Fix one problem, reveal another. 🎭
Just as we celebrated eliminating TLS errors, a new issue surfaced—thanks to our bigger, busier nodes. With more pods starting up per node, we quickly hit the kubelet’s image pull QPS and burst limits.
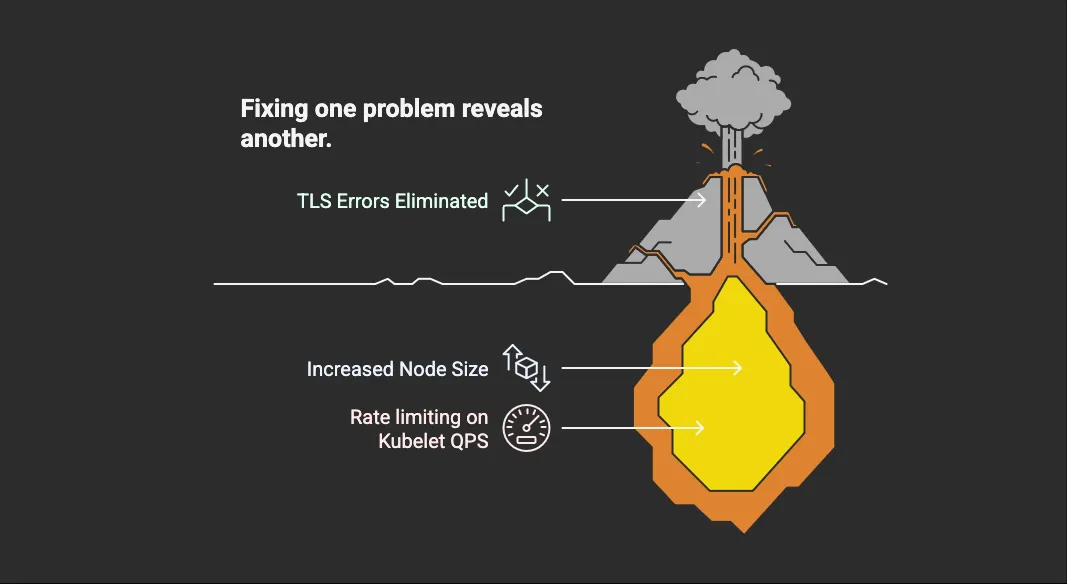
Fortunately, the fix was simple: we increased those limits in the kubelet config, and startup delays disappeared.
Final Thoughts
This migration was part of a broader effort to move away from GitLab’s Docker+Machine executor, an end-of-life solution that was approximately 70% slower in CI job start/queue time.
Deploying GitLab Runner on Kubernetes came with its share of challenges and early growing pains, but ultimately delivered a significantly faster experience for all of our engineers. Maintenance and customization of org-specific pipeline behavior have been straightforward thanks to the modular nature of runner images and the Kubernetes architecture too!
Additionally, self hosting the runners within our own network also enabled secure communication with internal services, making it a solid move for both security and complex automations.
This has been a major focus area for me over the past few years, so stay tuned for more deep dives across different aspects of this journey.