Published
- 4 min read
Part 1: Build vs Buy – Delivering an Internal Developer Portal
Link Copied!
Share away.
Context
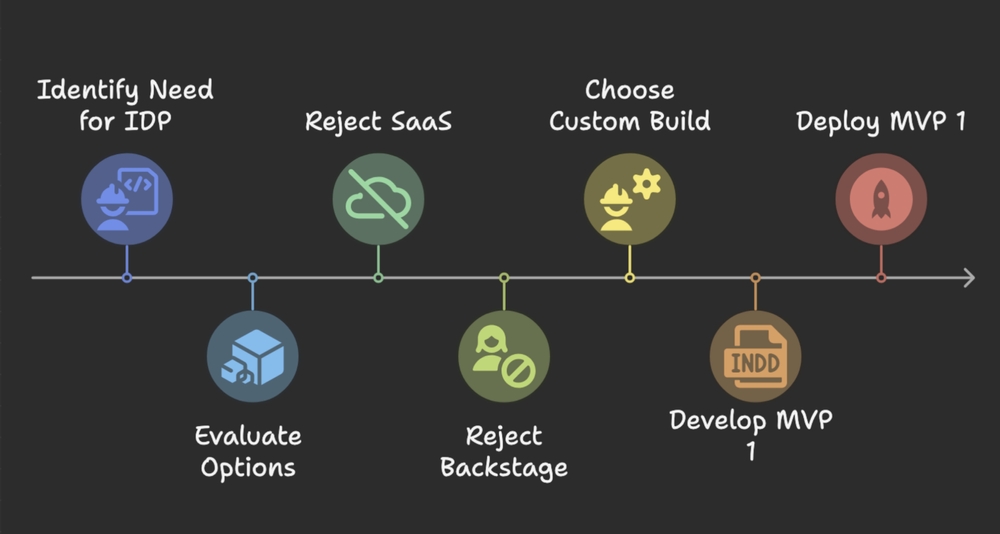
After two years working on our core platform (PaaS) team, I stepped away to lead a new DevEx team within our platform vertical. Our mission was clear: improve visibility, reduce friction, and empower engineers across the org. One of the first challenges we tackled was building an Internal Developer Portal (IDP).
We knew internal visibility wasn’t broken — but it wasn’t easy either. Engineers often struggled to find services, understand ownership, or figure out who to talk to. We looked at everything: SaaS platforms, open source tools like Backstage, and building it ourselves. After weighing the tradeoffs around cost, flexibility, and control, we chose to build from the ground up.
Here’s how we got to that decision.
Gathering requirements
The initial problem was simple: engineers couldn’t easily find out what existed, who owned it, or how to get in touch. The portal needed to:
- Make it easy to find team services and infrastructure
- Let engineers contact teams directly
- Require zero onboarding effort to start using it
Longer-term, we also wanted to:
- Support a dynamic org chart with detailed verticals, teams, and ownership mappings
- Offer software/project templates to standardize common workflows
- Provide scorecards and campaign tools to boost engineering engagement
- Help teams stay current with platform-wide changes and improvements
- Support for engineering scorecards and campaigns
- Templates for common setups (new services, APIs, etc.)
- A way to surface platform changes and drive adoption
The options
| Option | Type | Tools | Notes |
|---|---|---|---|
| SaaS | Paid | OpsLevel, Cortex | Quick to get started, but high cost and limited flexibility |
| Open Source | OSS | Backstage | Popular choice, but rigid model and heavy lift to customize |
| Custom Build | Internal | Python/Golang, OpenAPI | Total control, but requires ongoing maintenance and investment |
Why SaaS wasn’t right
We explored a couple of SaaS platforms, and while they looked good on the surface, they came some heafty with downsides:
- Recurring costs were high — especially for the features we’d actually need
- Integrations meant **handing over sensitive data **— some providers even required admin access, with no/little support for PoLP RBAC.
- Some flexibility only came with the most expensive tiers
- Security/compliance teams weren’t keen on exposing internal infra data externally
Why we passed on Backstage
Backstage was the most promising open source option, but we hit some real blockers early on:
- The data model is fixed — hard to express how we think about teams and ownership
- Relationships are limited — Backstage doesn’t allow specifying multiple, distinct relationships between entities, which leads to less granularity and confusion around resource dependencies
- Team dashboards aren’t supported out of the box
- Managing repo-level YAML isn’t scalable for us — an immediate violation of our early requirements
- The plugin architecture is powerful, but also a steep learning curve
Several engineers in our org had already attempted to self-host and explore Backstage independently. One engineer summarised the sentiment well:
“Despite trying to push this forward a year ago, I saw Backstage as a nice-to-have, not a must-have. People talk about it enthusiastically because it’s trending, but at its core what they want is a user-friendly service registry — a place to look up deployed services, who owns them, and get repo links or documentation. That part I get. But once I hit their messy setup and poor docs, I dropped the towel.”
Another aspect some liked was the idea of using Backstage to scaffold services through templates. While that sounded useful for some teams, it didn’t align with our top priorities, and came with steep customization effort.
In short, it didn’t solve our core needs without a lot of work — and for the engineers who explored it early, it didn’t offer enough value to justify the hassle.
Links
- https://www.port.io/blog/what-are-the-technical-disadvantages-of-backstage
- https://www.reddit.com/r/devops/comments/10guddj/comment/j5az4ow/
- https://newsletter.pragmaticengineer.com/p/backstage
Why we decided to build
In the end, building gave us the most flexibility with fewer long-term tradeoffs:
- As a CapEx team, investing time upfront makes more sense than paying SaaS bills forever
- We picked tech that suits us — Python for the backend, React for the frontend, and OpenAPI for structured contracts holding it all together. A typical modern stack!
- We planned to build internal collectors (
AWS,k8s,Active Directory), but those details came later — we’ll cover the implementation specifics in Part 2 - We could easily define our own data models unique to our org and make them available over APIs, instead of bending to someone else’s
- And we didn’t need to wait for vendors or fight with their roadmaps
What we shipped first
Our MVP focused on the essentials:
- A catalog of services, resources, and teams
- Contact details and ownership mapping
- Infra visibility pulled from AWS and Kubernetes
- A recurring collection and ingestion system ensured a 1:1 mapping between our product and multiple AWS environments
It wasn’t fancy — just a simple model that delivered what we needed. And that simplicity was intentional. I wanted a system that was lightweight and maintainable, not complicated or over-engineered. Engineers could find stuff and get unblocked — and it provided real business value, making it genuinely useful to both technical and non-technical users.
Next up: we’ll jump into the high-level implementation details — how we modeled the relationships between teams and services, and kept the whole thing fast, lightweight, and easy to extend.